

BFS und DFS sind die beim Durchsuchen eines Diagramms verwendeten Verfahrmethoden. Graph Traversal ist der Prozess des Besuchens aller Knoten des Graphen. Ein Graph ist eine Gruppe von Scheitelpunkten 'V' und Kanten 'E', die mit den Scheitelpunkten verbunden sind.
Vergleichstabelle
| Basis zum Vergleich | BFS | DFS |
|---|---|---|
| Basic | Vertex-basierter Algorithmus | Kantenbasierter Algorithmus |
| Datenstruktur zum Speichern der Knoten | Warteschlange | Stapel |
| Speicherverbrauch | Ineffizient | Effizient |
| Struktur des konstruierten Baumes | Breit und kurz | Schmal und lang |
| Mode durchqueren | Älteste nicht besuchte Ecken werden zuerst untersucht. | Scheitelpunkte entlang der Kante werden am Anfang untersucht. |
| Optimalität | Optimal für die Suche nach der kürzesten Entfernung, nicht in den Kosten. | Nicht optimal |
| Anwendung | Untersucht den bipartiten Graphen, die verbundene Komponente und den kürzesten Pfad in einem Graphen. | Untersucht einen zweigleisigen verbundenen Graphen, einen stark verbundenen Graphen, einen azyklischen Graphen und die topologische Reihenfolge. |
Definition von BFS
Breadth First Search (BFS) ist die in Graphen verwendete Durchlaufmethode. Es verwendet eine Warteschlange zum Speichern der besuchten Scheitelpunkte. Bei dieser Methode liegt der Schwerpunkt auf den Scheitelpunkten des Diagramms. Zuerst wird ein Scheitelpunkt ausgewählt, dann wird er besucht und markiert. Die an den besuchten Knoten angrenzenden Knoten werden anschließend besucht und in der Warteschlange nacheinander gespeichert. In ähnlicher Weise werden die gespeicherten Scheitelpunkte nacheinander behandelt und ihre benachbarten Scheitelpunkte werden besucht. Ein Knoten wird vollständig erforscht, bevor er einen anderen Knoten in der Grafik besucht. Mit anderen Worten, er durchforstet flachste unerforschte Knoten zuerst.
Beispiel
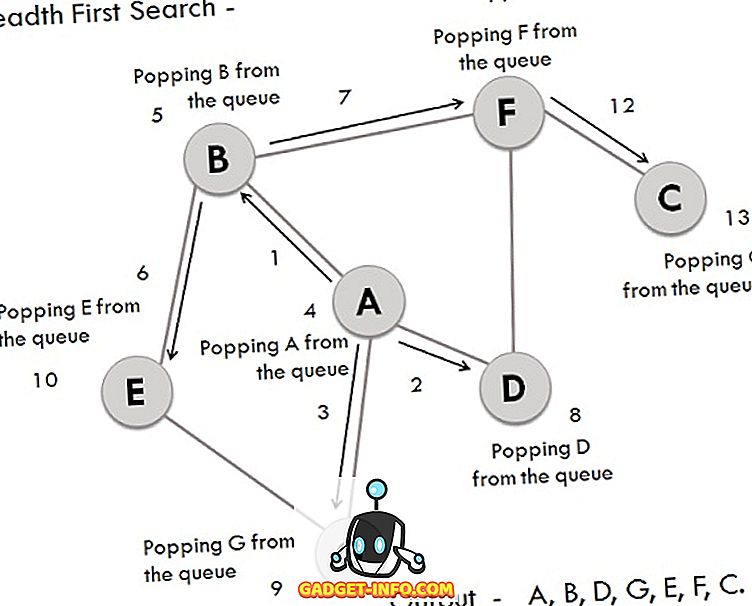
Wir haben einen Graphen, dessen Scheitelpunkte A, B, C, D, E, F, G sind. Betrachten wir A als Startpunkt. Die im Prozess beteiligten Schritte sind:
- Scheitelpunkt A wird erweitert und in der Warteschlange gespeichert.
- Die Scheitelpunkte B, D und G von A werden erweitert und in der Warteschlange gespeichert, während der Scheitelpunkt A entfernt wird.
- Nun wird B am vorderen Ende der Warteschlange entfernt und die Nachfolger-Scheitelpunkte E und F gespeichert.
- Der Scheitelpunkt D wird am vorderen Ende der Warteschlange entfernt und sein verbundener Knoten F wird bereits besucht.
- Der Scheitelpunkt G wird aus der Warteschlange entfernt und hat einen Nachfolger E, der bereits besucht wird.
- Nun werden E und F aus der Warteschlange entfernt und der nachfolgende Knoten C wird durchlaufen und in der Warteschlange gespeichert.
- Zum Schluss wird auch C entfernt und die Warteschlange ist leer, was bedeutet, dass wir fertig sind.
- Die erzeugte Ausgabe ist - A, B, D, G, E, F, C.

BFS kann hilfreich sein, um herauszufinden, ob der Graph Komponenten angeschlossen hat oder nicht. Und es kann auch zum Erkennen eines zweiteiligen Graphen verwendet werden .
Ein Diagramm ist zweiteilig, wenn die Scheitelpunkte des Diagramms in zwei getrennte Sätze unterteilt sind. Keine zwei benachbarten Scheitelpunkte würden sich in derselben Gruppe befinden. Eine andere Methode zum Überprüfen eines zweiteiligen Diagramms besteht darin, das Auftreten eines ungeraden Zyklus in dem Diagramm zu überprüfen. Ein zweiteiliger Graph darf keinen ungeraden Zyklus enthalten.
BFS ist auch besser darin, den kürzesten Pfad in der Grafik als Netzwerk zu finden.
Definition von DFS
Das DFS- Durchlaufverfahren (Depth First Search) verwendet den Stapel zum Speichern der besuchten Scheitelpunkte. DFS ist die kantenbasierte Methode und arbeitet auf rekursive Weise, wobei die Scheitelpunkte entlang eines Pfades (Kante) untersucht werden. Die Erkundung eines Knotens wird unterbrochen, sobald ein anderer nicht erforschter Knoten gefunden wird und die tiefsten nicht erforschten Knoten zuerst durchlaufen werden. DFS durchquert / besucht jeden Scheitelpunkt genau einmal und jede Kante wird genau zweimal geprüft.
Beispiel
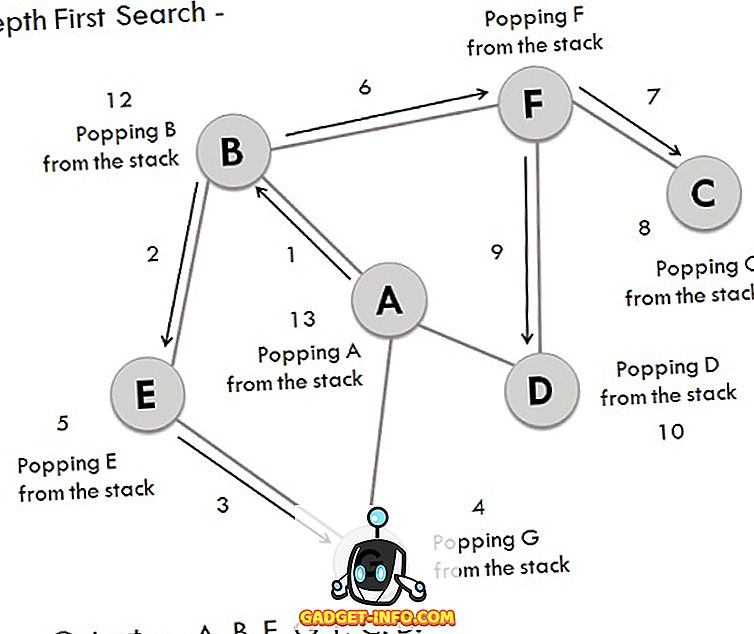
Ähnlich wie bei BFS können Sie dasselbe Diagramm für die Durchführung von DFS-Vorgängen verwenden, und die erforderlichen Schritte sind:
- Betrachten von A als Startscheitelpunkt, der erforscht und im Stapel gespeichert wird.
- Der Nachfolger-Scheitelpunkt von A wird im Stapel gespeichert.
- Scheitelpunkt B hat zwei Nachfolger E und F, darunter alphabetisch zuerst E und wird im Stapel gespeichert.
- Der Nachfolger von Scheitelpunkt E, dh G, wird im Stapel gespeichert.
- Scheitelpunkt G hat zwei verbundene Scheitelpunkte, und beide werden bereits besucht, sodass G aus dem Stapel herausspringt.
- In ähnlicher Weise wird auch E entfernt.
- Jetzt befindet sich Scheitelpunkt B am oberen Rand des Stapels. Sein anderer Knoten (Scheitelpunkt) F wird untersucht und im Stapel gespeichert.
- Vertex F hat zwei Nachfolger C und D, dazwischen wird C zuerst durchlaufen und im Stapel gespeichert.
- Scheitelpunkt C hat nur einen Vorgänger, der bereits besucht wurde, also wird er vom Stapel entfernt.
- Nun wird der mit F verbundene Knoten D besucht und im Stapel gespeichert.
- Da Scheitelpunkt D keine nicht besuchten Knoten hat, wird D entfernt.
- In ähnlicher Weise werden auch F, B und A angezeigt.
- Die erzeugte Ausgabe ist - A, B, E, G, F, C, D.

Die Anwendungen von DFS umfassen die Prüfung von zwei randverknüpften Graphen, stark verbundenen Graphen, azyklischen Graphen und topologischer Reihenfolge .
Ein Graph wird nur dann als zwei verbundene Kanten bezeichnet, wenn er auch dann verbunden bleibt, wenn eine seiner Kanten entfernt wird. Diese Anwendung ist sehr nützlich in Computernetzwerken, in denen der Ausfall einer Verbindung im Netzwerk das verbleibende Netzwerk nicht beeinträchtigt und es weiterhin verbunden ist.
Ein stark verbundener Graph ist ein Graph, in dem ein Pfad zwischen einem geordneten Scheitelpaar vorhanden sein muss. DFS wird im gerichteten Graphen verwendet, um den Pfad zwischen jedem geordneten Scheitelpaar zu suchen. DFS kann Verbindungsprobleme leicht lösen.
Hauptunterschiede zwischen BFS und DFS
- BFS ist ein vertexbasierter Algorithmus, während DFS ein kantenbasierter Algorithmus ist.
- Die Warteschlangendatenstruktur wird in BFS verwendet. DFS verwendet dagegen Stack oder Rekursion.
- Speicherplatz wird in DFS effizient genutzt, während die Speicherplatznutzung in BFS nicht effektiv ist.
- BFS ist ein optimaler Algorithmus, während DFS nicht optimal ist.
- DFS baut schmale und lange Bäume. Im Gegensatz dazu erstellt BFS einen breiten und kurzen Baum.
Fazit
BFS und DFS, beide Diagrammsuchtechniken haben eine ähnliche Laufzeit, aber unterschiedlichen Speicherplatzverbrauch. DFS nimmt linearen Speicherplatz in Anspruch, da wir uns einen einzelnen Pfad mit nicht erforschten Knoten merken müssen, während BFS jeden Knoten im Speicher behält.
DFS führt zu tieferen Lösungen und ist nicht optimal, funktioniert jedoch gut, wenn die Lösung dicht ist, während BFS optimal ist, was zunächst das optimale Ziel sucht.