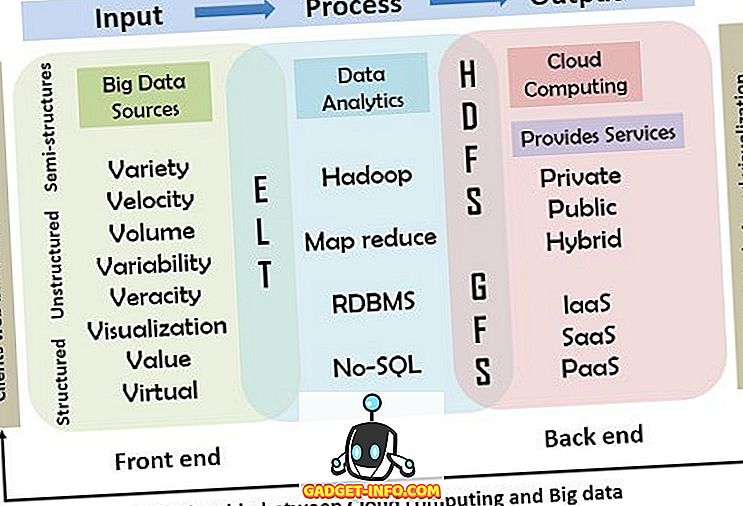
Es handelt sich dabei um das Eingabe-, Verarbeitungs- und Ausgabemodell, das im Folgenden erläutert wird. Das Diagramm veranschaulicht die Beziehung zwischen Cloud Computing und Big Data im Detail.
Vergleichstabelle
| Basis zum Vergleich | Cloud Computing | Große Daten |
|---|---|---|
| Basic | On-Demand-Dienste werden unter Verwendung integrierter Computerressourcen und -systeme bereitgestellt. | Umfangreiche strukturierte, unstrukturierte, komplexe Daten, die die Verarbeitung der traditionellen Verarbeitungstechniken verbieten. |
| Zweck | Ermöglichen Sie, dass die Daten auf dem Remote-Server gespeichert und verarbeitet werden und von jedem Ort aus darauf zugegriffen werden kann. | Organisation der großen Daten- und Informationsmenge, um wertvolles Wissen zu extrahieren. |
| Arbeiten | Verteiltes Rechnen wird zur Analyse der Daten und zur Erzeugung nützlicherer Daten verwendet. | Das Internet wird zur Bereitstellung der Cloud-basierten Dienste verwendet. |
| Vorteile | Geringer Wartungsaufwand, zentrale Plattform, Bereitstellung von Backup und Wiederherstellung. | Kostengünstiger Parallelismus, skalierbar, robust. |
| Herausforderungen | Verfügbarkeit, Transformation, Sicherheit, Lademodell. | Datenvielfalt, Datenspeicherung, Datenintegration, Datenverarbeitung und Ressourcenverwaltung. |
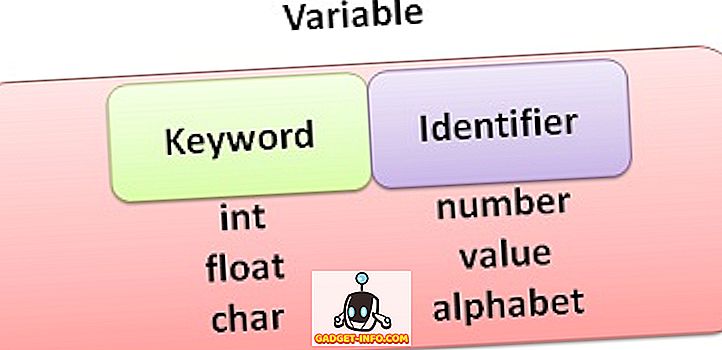
Definition von Cloud Computing
Cloud Computing stellt eine integrierte Plattform für Dienste bereit, mit der beliebige Datenmengen jederzeit und an jedem Ort über das Hochgeschwindigkeits-Internet gespeichert und abgerufen werden können. Cloud ist eine breite Palette terrestrischer Server, die über das Internet verteilt sind, um die Daten zu speichern, zu verwalten und zu verarbeiten. Das Cloud-Computing ist so entwickelt, dass die Entwickler das Web-Scale-Computing leicht implementieren können. Die Entwicklung des Internets hat das Cloud-Computing-Modell hervorgebracht, da das Internet die Grundlage des Cloud-Computing ist. Damit das Cloud Computing effizient funktioniert, benötigen wir eine Hochgeschwindigkeits-Internetverbindung. Es bietet eine flexible Umgebung, in der die Kapazität und Fähigkeiten dynamisch hinzugefügt und gemäß der Pay-per-Use-Strategie verwendet werden können.
Das Cloud-Computing verfügt über einige wesentliche Eigenschaften: Ressourcenpooling, On-Demand-Self-Service, breiter Netzwerkzugang, gemessener Service und schnelle Elastizität. Es gibt vier Arten von Clouds - Public, Private, Hybrid und Community.
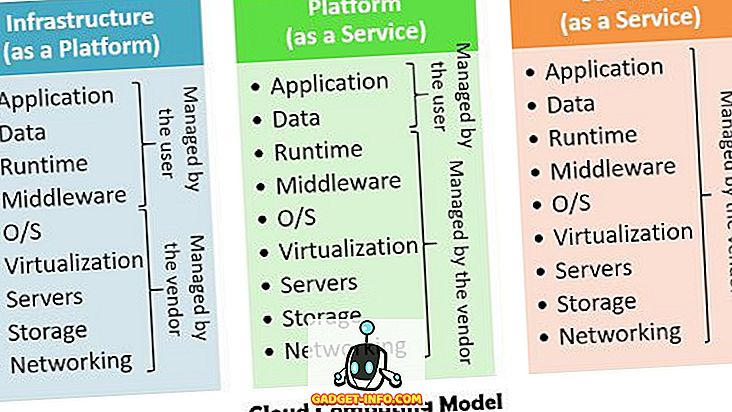
Grundsätzlich gibt es drei Cloud-Computing-Modelle - Platform as a Service (Paas), Infrastruktur as a Service (Iaas), Software as a Service (Saas), die sowohl Hardware als auch Softwaredienste verwenden.
- Infrastruktur als Dienst - Dieser Dienst wird zur Bereitstellung der Infrastruktur verwendet, die Speicherverarbeitungsleistung und virtuelle Maschinen umfasst. Es implementiert die Virtualisierung von Ressourcen auf Basis von Service Level Agreements (SLAs).
- Platform as a Service - Plattform als Service - über der IaaS-Schicht, die eine Programmier- und Laufzeitumgebung bietet, in der die Benutzer Cloud-Anwendungen bereitstellen können.
- Software as a Service - Er liefert die Anwendungen an den Client, die direkt auf dem Cloud-Anbieter ausgeführt werden.

Definition von Big Data
Die Daten werden mit der Zunahme von Volumen, Vielfalt, Geschwindigkeit und damit über die Fähigkeiten der IT-Systeme hinaus zu großen Daten, die wiederum Schwierigkeiten beim Speichern, Analysieren und Verarbeiten der Daten verursachen. Einige Organisationen haben die Ausrüstung und das Fachwissen entwickelt, um mit dieser Art massiver Mengen strukturierter Daten umzugehen, aber die exponentiell steigenden Datenmengen und der schnelle Datenfluss stellen die Fähigkeit ein, diese Daten abzubauen und umgehend umsetzbare Informationen zu generieren. Diese umfangreichen Daten können nicht auf normalen Geräten gespeichert und in der verteilten Umgebung verteilt werden. Big Data Computing ist ein erstes Konzept der Datenwissenschaft, das sich auf multidimensionales Informations-Mining für wissenschaftliche Entdeckungen und Geschäftsanalysen für große Infrastrukturen konzentriert.
Die grundlegenden Dimensionen der Big Data sind Volumen, Geschwindigkeit, Vielfalt und Richtigkeit, die ebenfalls oben erwähnt wurden. Später werden zwei weitere Dimensionen entwickelt, die Variabilität und Wert sind.
- Volume ( Volumen) - Zeigt die zunehmende Größe von Daten an, deren Verarbeitung und Speicherung bereits problematisch ist.
- Geschwindigkeit - Dies ist der Fall, in dem die Daten erfasst werden und die Flussgeschwindigkeit der Daten.
- Vielfalt - Die Daten sind nicht immer in einer einzigen Form vorhanden, es gibt verschiedene Formen der Daten, z. B. Text, Audio, Bild und Video.
- Zuverlässigkeit - Dies wird als Zuverlässigkeit der Daten bezeichnet.
- Variabilität - Beschreibt die Vertrauenswürdigkeit, Komplexität und Inkonsistenzen der Big Data.
- Wert - Die ursprüngliche Form des Inhalts ist möglicherweise nicht sehr nützlich und produktiv. Daher werden die Daten analysiert und Daten mit hohem Wert ermittelt.
Hauptunterschiede zwischen Cloud Computing und Big Data
- Cloud Computing ist der Computing-Service, der bei Bedarf bereitgestellt wird, indem über das Internet verteilte Computing-Ressourcen verwendet werden. Auf der anderen Seite sind die großen Daten eine riesige Menge von Computerdaten, einschließlich strukturierter, unstrukturierter, halbstrukturierter Daten, die mit den herkömmlichen Algorithmen und Techniken nicht verarbeitet werden können.
- Das Cloud-Computing bietet den Benutzern eine Plattform, auf die Dienste wie Saas, Paas und Iaas auf Abruf in Anspruch genommen werden können, und es berechnet den Service je nach Nutzung. Im Gegensatz dazu besteht das Hauptziel von Big Data darin, das verborgene Wissen und die Muster aus einer riesigen Sammlung von Daten zu extrahieren.
- Eine Hochgeschwindigkeits-Internetverbindung ist die wesentliche Voraussetzung für das Cloud Computing. Im Gegensatz dazu verwendet Big Data verteiltes Rechnen, um die Daten zu analysieren und abzubauen.
Beziehung zwischen Cloud Computing und Big Data
Das folgende Diagramm veranschaulicht die Beziehung und Funktionsweise des Cloud-Computing mit Big Data. In diesem Modell wird das primäre Eingabe-, Verarbeitungs- und Ausgabeberechnungsmodell als Referenz verwendet, in der die großen Daten unter Verwendung von Eingabegeräten wie Maus, Tastatur, Mobiltelefonen und anderen intelligenten Geräten in das System eingefügt werden. Die zweite Verarbeitungsstufe umfasst die Werkzeuge und Techniken, die von der Cloud zur Bereitstellung der Dienste verwendet werden. Zuletzt wird das Ergebnis der Verarbeitung an die Benutzer übermittelt.
Fazit
Die Cloud-Computing-Technologie bietet ein geeignetes und kompatibles Framework für Big Data, das sich durch einfache Handhabung, Zugriff auf Ressourcen, niedrige Kosten für Ressourcennutzung bei Angebot und Nachfrage auszeichnet und zudem den Einsatz von soliden Geräten für den Umgang mit Big Data minimiert. Sowohl Cloud als auch Big Data legen Wert darauf, den Wert eines Unternehmens zu steigern und gleichzeitig die Investitionskosten zu senken.